Faktoriál pojem jen málo pochopený.
Začnu tím, že budu uvádět o faktoriálu to, co uvádí jiné zdroje. Za všechny budu citovat českou Wikipedii z odkazu na Faktoriál Wikipedie.cz : –
V matematice je faktoriál čísla n (značeno pomocí vykřičníku: n!) číslo, rovné součinu všech kladných celých čísel menších nebo rovných n, pokud je n kladné a 1 pokud n = 0. Značení n! vyslovujeme jako „n-faktoriál“. Toto značení zavedl Christian Kramp v roce 1808.
Následuje definice s podobou zápisu vzorcem. Ovšem to se prakticky obsahem neliší od odkazu z Wikipedie.org. Zde Factorial Wikipedie.en. Také citujeme : –
In mathematics, the factorial of a non-negative integer n, denoted by n!, is the product of all positive integers less than or equal to n. For example,
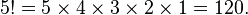
The value of 0! is 1, according to the convention for an empty product.[1]
The factorial operation is encountered in many areas of mathematics, notably in combinatorics, algebra and mathematical analysis. Its most basic occurrence is the fact that there are n! ways to arrange n distinct objects into a sequence (i.e., permutations of the set of objects). This fact was known at least as early as the 12th century, to Indian scholars.[2] The notation n! was introduced by Christian Kramp in 1808.[3]
Podobnost mezi oběma citacemi není v ničem jiném, nežli v tom, že začínají tím, k čemu se faktoriál používá. Ani slovo o tom, co to je. Nebylo by to divné, kdyby v popisu slovních definic kombinací a variací také nic takového nebylo. Ale je tam slovní definice, která se vztahuje ke specifikaci množiny. Nebo spíš bych měl vyjádřit že k odlišnosti mezi ostatními kombinatorickými množinami
Kombinace Wikipedie.cz. Citace : Kombinace k-té třídy z n prvků je skupina k prvků vybraných z celkového počtu n prvků, přičemž při výběru nezáleží na pořadí jednotlivých prvků. Rozlišujeme kombinace s opakováním a bez opakování.
Variace z carolina.mff.cuni.cz Citace : k-členná variace z n prvků je uspořádaná k-tice sestavená z těchto prvků tak, že každý se v ní vyskytuje nejvýše jednou.
Variace Wikipedia_de. Citace : Eine Variation (von lateinisch variatio „Veränderung“) oder geordnete Stichprobe ist in der Kombinatorik eine Auswahl von Objekten in einer bestimmten Reihenfolge. Können Objekte dabei mehrfach ausgewählt werden, so spricht man von einer Variation mit Wiederholung, darf jedes Objekt nur einmal auftreten von einer Variation ohne Wiederholung. Die Ermittlung der Anzahl möglicher Variationen ist eine Standardaufgabe der abzählenden Kombinatorik.
Z toho můžeme vyvodit jediné. Faktoriál není množinou ve stejném smyslu jako pojmy ostatní (kombinace, variace). Uvádí se sice, že má veliké využití, ale je to jen výpočet množství. To vůbec není pravda. Faktoriál je stejným pojmem v kombinatorice jako ostatní pojmy – jedná se o množinu. Musíme tedy ještě upřesnit skutečnost, že všechny kombinatorické (základní) pojmy mají dvojí charakter. Charakter výpočtu množství a charakteristiku množiny prvků.
A nyní ještě maličkost. Spíš provokativní otázka : Proč je faktoriál jen výpočtem, když variace jsou množinou a permutace dokonce nadmnožinou?
Není snad pravdou toto : Factorial(n) ≡ Variace(n, k=n) ≡ Permutace(n) ?
Vždyť je do očí bijící skutečností, že každý základní kombinatorický pojem je možné vyjádřit pomocí faktoriálu, ale naopak to neplatí! Není náhodou pojem Permutací jen duplicitním označením Faktoriálu? Proč v definicích (vzorcích) není místo faktoriálu užit výraz pro Permutace? Tedy proč místo n! není užíván výraz P(n)
Částečnou odpovědí je to, že Faktoriál nemá třídu. To je celkem přijatelné vysvětlení, ale pokud platí n! =(≡) Variace(n, k=n) pak vlastně třídu má. Ale nemá výběr který je definován jako k ≤ n. Stačilo by k pochopení vyjádřit (n,n)!? To je stejně účelné jako potřebné – tedy vlastně vůbec. Jen opět otázka jako malý test → má Permutace třídy? Také ne! A přes to se ví, že je to nadmnožina!
Není to podobný případ jako s „Božím jménem“? Vždyť se vykládá, že za trest jsme Boží jméno zapoměli. Židé, křesťané a islám uctívají stejného boha, ale každý mu říká jinak. To by nebylo až tak zlé, když by každý z nich netvrdil, že jen on má pravdu a kdyby kvůli tomu nebyly války. A ještě si k tomu neodpustím dodat, že popletení řeči je typický „Boží prostředek“ zejména pokud chce bůh potrestat lidskou pýchu.
Vyjádříme si faktoriál jako vzorec pro výpočet množství. To je současně také algoritmus pro vygenerování množiny „faktoriál“. Postup je velice jednoduchý a je uveden v rámci citace anglické Wikipedie.
Konkrétně v obecném vyjádření : n! = n * (n-1) * (n-2) *.*.*….* 1.
Pro zrealizování výpočtu přichází v úvahu například array(n[0]=1, n[1]=2,.,.,., n[n-1]=n). Takže vytvoříme array a faktoriál = součin n[0]=1…až n[n-1]=n.
Ve spojitosti s tím se ale přímo nabízí užití například cyklu for. Určíme, že výsledek (proměnná jako číslo) je fact.
fact = 1
for iCount = 1 To n
fact = fact*iCount
next iCount
To je algoritmus pro vyjádření množství. Je celkem jedno jakou použijeme metodu. Zda cyklus, nebo součin hodnot z array, který se samozřejmě provádí také pomocí cyklu. Jde jen o to, zda potřebujeme vygenerovat spolu s množstím také množinu. Právě vygenerování množiny už array potřebuje.
K vlastnímu vytvoření množiny se ale spíš hodí výpočet obrácený. Tedy v array je první položka dána jako n a poslední 1. To můžeme pochopit z grafického vyjádření. Za základ Faktoriálu považujeme výraz n^n. Potom první pozice vybírá 1 z (n). Druhá pozice z leva vybírá 1 z (n-1). Je zde vynecháno číslo použité v první pozici. A tak se pokračuje dál až zbyde jediné číslo.
Pro lexikální řazení platí, že na první pozici (1. řádek) je nejmenší číslo (jednička). Pro alternativy všech řádků začínajících číslem jedna už přichází opravdu jen čísla (2 až n). Takže je li na první pozici například číslo 4, pro druhou pozici přichází v úvahu všechna ostatní čísla (n – 1) tedy mimo čísla 4. Podobně pro všechny ostatní pozice. Například pro faktoriál čísla 6 a konkrétní řádek 4, 1, 2, 3, 5, 6 : –
|
pozice 1 ↓ |
pozice 2 ↓ |
pozice 3↓ |
pozice 4↓ |
pozice 5↓ |
pozice 6↓ |
|
1 |
1 |
Ø |
Ø |
Ø |
Ø |
|
2 |
2 |
2 |
Ø |
Ø |
Ø |
|
3 |
3 |
3 |
3 |
Ø |
Ø |
|
4 |
Ø |
Ø |
Ø |
Ø |
Ø |
|
5 |
5 |
5 |
5 |
5 |
Ø |
|
6 |
6 |
6 |
6 |
6 |
6 |
|
Σ↑ = 6 |
Σ↑ = 5 |
Σ↑ = 4 |
Σ↑ = 3 |
Σ↑ = 2 |
Σ↑ = 1 |
Potom může vypadat podstata kódu například takto :
pozice 1 = array1(1, 2, 3, 4, 5, 6)
pozice 2 = array2(1, 2, 3, 5, 6)
pozice 3 = array3(2, 3, 5, 6)
pozice 4 = array4(3, 5, 6)
pozice 5 = array5(5, 6)
pozice 6 = array6(6)
Pro každou pozici platí funkce INT (integer jako celočíselná část podílu). Konkrétně jde o opakování stejného čísla v první pozici.
Pro lexikální algoritmus je to začátek 1, 2, 3, 4, 5, 6 : –
1. pozice ______________________________________
6! = 720 proto každé ze 6 – ti čísel se opakuje 720/6 = 5! tedy 120 x za sebou.
1-120 opakuje se stále číslo 1
121-240 opakuje se stále číslo 2
241-360 opakuje se stále číslo 3
……
601-720 opakuje se stále číslo 6
2. pozice ______________________________________
5! = 120 proto každé ze 5 – ti zbylých čísel se opakuje 120/5 = 4! tedy 24 x za sebou. Toto opakování ve druhé pozici je bez čísla v první pozici a to je největší problém algoritmu.
1-24 opakuje se stále číslo 2
25-48 opakuje se stále číslo 3
……
67-120 opakuje se stále číslo 6
3. pozice ______________________________________
4! = 24 proto každé ze 4 zbylých čísel se opakuje 24/4 = 3! tedy 6 x za sebou. Toto opakování ve třetí pozici je bez čísla v první a druhé pozici a to je největší problém algoritmu.
1-6 opakuje se stále číslo 3
7-12 opakuje se stále číslo 4
……
19-24 opakuje se stále číslo 6
4. pozice ______________________________________
3! = 6 proto každé ze 3 zbylých čísel se opakuje 6/3 = 2! tedy 2 x za sebou. Toto opakování ve čtvrté pozici je bez bez čísla v první, druhé a třetí pozici a to je největší problém algoritmu.
1-2 opakuje se stále číslo 4
3-4 opakuje se stále číslo 5
5-6 opakuje se stále číslo 6
5. pozice ______________________________________
2! = 2 proto každé ze 2 zbylých čísel opakuje 2/2 = 1! tedy 1x. Toto opakování v páté pozici je bez bez čísla v první, druhé, třetí a čtvrté pozici Zde je potřeba použít MODULO. Výše popsaný postup platí pro MOD = 0. Je – li MOD = 1, potom se vybere to druhé ze 2 čísel.
1-1 opakuje se stále číslo 5
2-2 opakuje se stále číslo 6
6. pozice ______________________________________
1! = 1 proto pro poslední pozici vždy nějaké číslo zbyde.
Problematika se dá řešit různě. Například pro každou pozici čísla 1 platí:
číslo 1 – INT = 0 – 1. pozice (1-120)
číslo 1 – INT = 1 – 2. pozice (121-240)
číslo 1 – INT = 2 – 3. pozice (241-360)
číslo 1 – INT = 3 – 4. pozice (361-480)
číslo 1 – INT = 4 – 5. pozice (481-600)
číslo 1 – INT = 5 – 6. pozice (601-720)
Totéž platí o druhé pozici, ale opakování se po 24x v rámci 1 cyklu 120 opakování. Takto se dá těleso sestrojit graficky, ale není to lexikální řazení. Poměrně pochopitelný je tento rozvoj jako „skládání sloupců“ : –
1! = 1
Vytvoříme množinu faktoriál čísla 1.
1
2! = 2
Vytvoříme množinu faktoriál čísla 2 tak, že přiřadíme nejprve číslo 2 do prava k číslu 1 a ve druhém řádku změníme jejich pořadí.
1 – 2
2 – 1
3! = 6
Množinu faktoriál čísla 3 vytvoříme tak, že přiřadíme nejprve číslo 3 do prava na každý řádek množiny čísla 2. Zkopírujeme rozšířenou množinu čísla 2 a sloupec nového čísla (3) prostřídáme na všech pozicích.
1 – 2 – 3
2 – 1 – 3
——-
1 – 3 – 2
2 – 3 – 1
——-
3 – 1 – 2
3 – 2 – 1
4! = 24
Množinu faktoriál čísla 4 vytvoříme z množiny faktoriálu 3 tak, že přiřadíme nejprve číslo 4 do prava na každý řádek množiny čísla 3. Zkopírujeme rozšířenou množinu čísla 3 a sloupec nového čísla (4) prostřídáme na všech pozicích.
1 – 2 – 3 – 4
2 – 1 – 3 – 4
1 – 3 – 2 – 4
2 – 3 – 1 – 4
3 – 1 – 2 – 4
3 – 2 – 1 – 4
———-
1 – 2 – 4 – 3
2 – 1 – 4 – 3
1 – 3 – 4 – 2
2 – 3 – 4 – 1
3 – 1 – 4 – 2
3 – 2 – 4 – 1
———-
1 – 4 – 2 – 3
2 – 4 – 1 – 3
1 – 4 – 3 – 2
2 – 4 – 3 – 1
3 – 4 – 1 – 2
3 – 4 – 2 – 1
———-
4 – 1 – 2 – 3
4 – 2 – 1 – 3
4 – 1 – 3 – 2
4 – 2 – 3 – 1
4 – 3 – 1 – 2
4 – 3 – 2 – 1
Konstrukce vyšších tříd faktoriálů probíhá stejně. Přidáváme na konec nižší třídy vyšší číslo a sloupce s nově přidaným číslem vykopírujeme a prostřídáme na každé pozici. Při tomto postupu původní jednotlivé sloupečky zůstávají v podobě beze změny. Jenom se „jakoby“ přemísťují aby se vytvořilo mezi nimi místo pro sloupec nových hodnot. Bohu žel jak bylo výše uvedeno není to lexikální algoritmus protože : –
1, 2, 3, 4 je správně na 1. pozici, ale
1, 2, 4, 3 je na 7. pozici a mělo by být na pozici 2.
Na druhou stranu je to velice jednoduchý algoritmus, nebo spíš mnemotechnická pomůcka. Podle tohoto návodu sestrojíte i poměrně objemné množiny faktoriálu v tabulkovém procesoru. Nakonec je setřídíte, což ale nemusí být tak jednoduché. Když použíjeme řetězec string (forma CSV), bude se řadit textově. Tedy nejdříve 1,10,11, a pak teprve 2,20,21,22 a tak dál. Proto dále uvádím postup pro třídění pomocí UV, tedy „Unique Value“, které je číslem. Postup pro n < 10 (jednociferné) je následující :-
1, 3, 6, 2, 5, 4 = 1*100000 + 3*10000 + 6*1000 + 2*100 + 5*10 + 4 = 136254 a je to skutečně číslo, které lze setřídit. Základním řádem je 10.
Pro čísla o dvou cifrách n < 100 je základním řádem 100. A tak dál. Podobnou možností je použít n- prvkový sytém ve smyslu například osmičkové, nebo hexadecimální soustavy. To je ale mnohem obtížnější, proto je velice výhodné používat pro UV dekadický řád.
Lexikální množina je na algoritmus nejnáročnější. Existuje více algoritmů, které vytvoří množinu, kterou je potřeba následně setřídit. Jsou to různé iterativní i rekurzivní postupy.
Existuje také více iterativních postupů, kterými se vygeneruje množina lexikální. To jsou ale postupy „nečisté“. Přeskakují například některé tvary protože se generuje z „variací s opakováním“.
Zcela jistě lze „čistou“ a „lexikální“ množinu vygenerovat pomocí rekurzivního algoritmu.
Připouštím, že to možná jde i pomocí iterativního a „čistého“ algoritmu, ale nevím o takovém. Sám jsem ho až do dnešního dne nesestrojil. To neznamená, že by to bylo vyloučeno.
Speciálním případem jsou vzorce pro tabulkové procesory. Vytvořil jsem takové vzorce (čísté a rekurzivní), ale není to nic jednoduchého (viz: Algoritmus faktoriál graficky). Musel jsem použít vzorce array (array formula). Mimo toho jsou závislé buď na systémovém řádku ROW(), nebo na pomocné buňce, která tuto potřebu splní ať je start vzorce kdekoliv.
Problém je podobný se vzorci a makry pro variace bez opakování. Pokud je však algoritmus variací bez opakování sestaven správně, umí vygenerovat i množinu faktoriál. Vzorce pro tabulkové procesory mají tvar jen pro faktoriál, ale vzorce pro variace bez opakování faktoriál zadání umí také, to opačně pro specializované vzorce faktoriál neplatí.
Specifikace množiny faktoriál :
Množina faktoriál je specifická tím, že prostřídá všechny variace uspořádání prvků v řádku. Popis vlastností množiny faktoriál je shodný s popisem množiny variací bez opakování.
